Today’s post will be a little different than usual. This time, we are not presenting a new model, but a description of the RAG method. The method is widely known, so this post will focus more on the problems that arise when implementing systems that use RAG than on the description of the method itself.
To explain RAG in a few words, it is an information retrieval method combined (in the results presentation layer) with a generative model/instruction model. The search mechanism and the reordering of search results are responsible for finding text fragments that contain the answer to the user’s question. The text fragments are then applied to the generative model in such a way that the model can use them to answer the user’s question. And that’s it in a nutshell 😉
So what can RAG be used for? Since it is a search method, it can obviously be used for all kinds of search engines. However, an important aspect that distinguishes RAG from the standard method of searching document collections is the introduction of a generative model (GenAI) to provide the final answer to the user. Thanks to the accuracy of the search engine itself and the ability of the GenAI model to answer questions based on context, RAG is ideal for searching and summarizing information scattered across multiple documents. Additionally, thanks to GenAI and its purpose of conducting chat conversations, we have the ability to influence the final form of the answer when asking a question. For example, imagine that we have a collection of documents in which we gather texts with different user opinions about various products. In this case, RAG would be ideal for answering the question:
What are the positive and negative opinions about product XYZ? Give three examples of positive and negative opinions and suggest responses to customer comments.
As you can see in the example, you can provide RAG not only with a search term, but also with detailed instructions on how to respond.
In fig. 1, we have broken down the RAG process into smaller and more specific steps. There are six main modules that symbolize issues throughout the RAG pipeline. The minimum path in such a pipeline is marked with a red dotted line and a red arrow. The green line and green arrow show the optimal path in the pipeline, which can be called RAG. In this post, we have briefly described the individual steps, and their detailed elaborations will be published in subsequent posts.
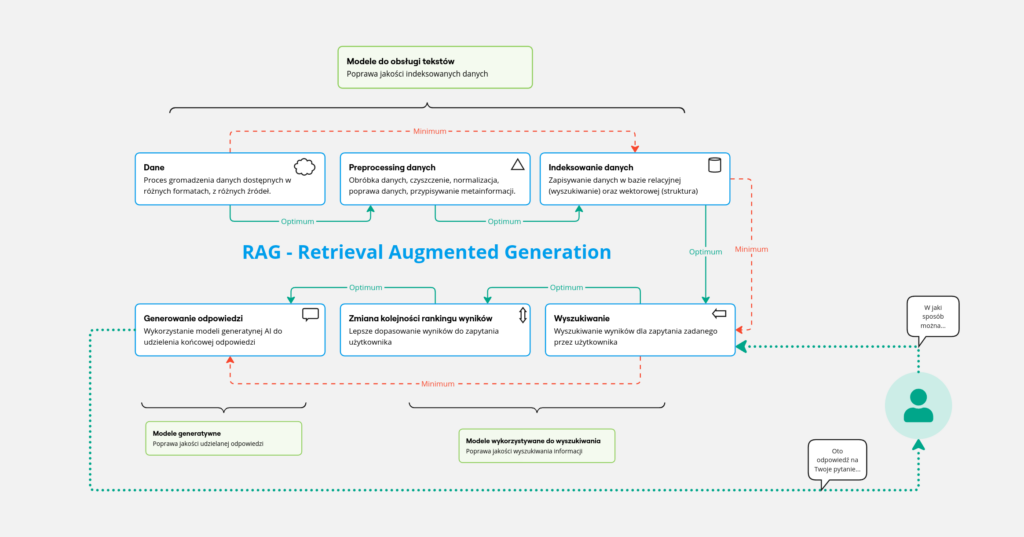
RAG in pieces
Data
Data is a fundamental element of any system that uses machine learning (ML) methods. Depending on the problem that such an ML system solves, it must be provided with appropriate data. In the case of RAG- data refers to all kinds of texts in which answers can be found. It may therefore seem that nowadays, when you can find everything on the internet, a lack of data should not be a problem… This is partly true, but for the most part it is not 😉
It is the abundance of data that introduces the problem of its location, availability under the appropriate license, and its quality, however understood. The selection of the origin of information from specific sources, the quality of the data itself, its readability, and detail are very important elements of the whole puzzle. Add to this the various file formats in which the information is stored (including pdf), and we are faced with the task of integrating different sources into a common format. It is important to remember that if we enter data into the system that contains false information, or contains too little information, or is not detailed enough, then a system using the RAG method will provide answers based on this data, which may be incorrect.
It is worth emphasizing once again that the final response of the system is generated on the basis of the data provided by the search engine. Therefore, if the search engine contains unreliable data, false and inaccurate information, then we will receive such responses. That is why it is worth taking the time to carefully select the set/create the collection of documents on which we will be working, and to take care of data preprocessing.
It is therefore safe to say that the quality of responses from such a system is strongly determined by the quality of the data used by that system.
Data Preprocessing
A very important element of the RAG system is data preprocessing, i.e., its initial processing. Before the data enters the further process, it is worth introducing a certain standard for its quality. The aforementioned diversity of data records causes problems with reading them correctly. Automatic processing of data downloaded from websites, docx files, and pdf introduces a lot of noise into the data. From the perspective of the RAG system, it is important that the data contains relevant information. When data is loaded automatically, for example from a pdf file, we will read not only the relevant fragments, but also a whole lot of text, including chapter headings, fragmented tabular data, or worse — completely unreadable data, such as this (e.g., when there are images in the pdf file that are also difficult to OCR):
4kV�#4T��##�_#�p��W#�_�|3��-�tg�\S�x�b�X��t�]*���\&/#��/�P�Of course, it is difficult to do anything about this situation, but it is worth detecting such files and not allowing the data to pass further, already at the pre-processing stage. In our previous post , we presented another problem with pdf files. After reading them, we get heavily distorted data, to quote an example from the post:
Strona...Tytuł...%6%z%50%|.....Zdecydowana0większość0czerwonych.karłów$należy#do,typu,widmowego%M,%ale%zalicza^się^do^nich^także^wieleHgwiazdHpóźnychHpodtypówHtypuHwidmowegoHKHorazHrzadkoHwystępujące,,najsłabsze,gwiazdy,typu,L.,Maksimum%intensywności%emitowanego%światła%przypada%w%zakresie%światła%czerwonego%lub%nawet%bliskiej%podczerwieni.From the perspective of further processing without proper cleaning of such data, this only causes problems. Indexing text that contains such illegible data will make it equally illegible for the search methods themselves. At this stage, it is important to be able to assess the data in terms of its quality and, as far as possible, bring it to a form close to ideal 😉 Is it worth introducing ML models for assessment and improvement at this stage?– Of course yes! Here is an example of how our T5 model works, cleaning texts from such situations:
Zdecydowana większość czerwonych karłów należy do typu widmowego M, ale zalicza się do nich także wiele gwiazd późnych podtypów typu widmowego K oraz rzadko występujące, najsłabsze gwiazdy typu L. Maksimum intensywności emitowanego światła przypada w zakresie światła czerwonego lub nawet bliskiej podczerwieni.Maybe not perfect, but this form is good 😉
What to do if your documents contain a lot of tables, drawings, or charts? It is worth considering using models that can interpret them and generate a description that can then be used to enrich the original text.
(…) It is also important to identify good and bad quality data and standardize it for further processing.
Data indexing
This is a very important process in the entire RAG. After preliminary data processing, the data must be saved in a database, where it will then be searched. At this stage, it is worth introducing parallel text indexing in both relational and vector databases. The relational database will help to arrange a longer document in its original structure, while the vector database will enable semantic searching. A very important element in the indexing process is the method of indexing. It is at this stage that we decide which information from the previous step will be indexed, and where and how.
First of all, we need to consider the purpose of the RAG system (specific field, specialist agent, general information) and select an appropriate model (embedder) that will “understand” the indexed content well enough. It is the embedder that creates vector representations of texts that are indexed in vector databases (e.g., Milvus), which are then searched. If, at this stage, the transformation of text into a vector is inaccurate, in other words, if we choose the wrong embedder model for the content we are indexing, this may result in poorer/less accurate quality in the comparison process. An indexing error can therefore be propagated to further processing steps. It is also important to choose the appropriate length of texts that are indexed as a single fragment. If the text is too long, it is worth dividing it into smaller parts called chunks — that is, one text is divided into several smaller fragments.
What if we index highly specific content for which no embedders are available? Of course, we are faced with the problem of finding another, more suitable model or training such a model from scratch. In one of our previous posts, we presented our preliminary embedder model, which was trained on web content.
(…) It is also important to select or train a specialist embedder and ensure appropriate indexing in databases.
Search
One could say that things are somewhat simplified here, because at the search stage we use the same mechanisms to translate text into vector representation as at the indexing stage… Nothing could be further from the truth. This is only the case when we limit the search process to counting the similarity of vectors representing the query to chunks in the database. Most often, the cosine of the angle between the query vector and the vectors stored in the vector database is calculated. These are the vectors that we stored during the data indexing stage. However, as we mentioned earlier, it depends on what information we index, and where and how.
If, at the indexing stage, we enrich the information about the indexed fragments with additional metadata, it is at this step that we are able to preliminarily filter out those chunks that are 100% incorrect. For example, if we enrich the description of a chunk with its category, then at this stage, before semantic comparison using a search engine, we can limit the search space only to those that come from the specified category.
Therefore, it is worth considering the option of limiting semantic search by additional dimensions. Will additional ML methods be useful for this? Of course they will. It is just a matter of imagination and the purpose of a given model.
(…) Additional meta-information about chunks can be very helpful during search, e.g., limiting results only to documents from a specific category.
Changing the order of ranking results
Okay, but what if, after filtering and searching for information, we still have trouble choosing which of the found chunks is the most relevant? This is where the process of reranking the order of results returned by the search engine comes in handy. One of the standard approaches is to use cross-encoders models, which, if properly trained, can determine the degree of relevance of the query to the chunk found. Of course, as in the case of an embedder, if the reranker model is not properly matched to the specifics of the data, the result may be the opposite of what is expected 😉
What should you do in such a situation? There are two main approaches:
- after gaining a better understanding of the field and conducting more thorough research, you can make a more informed choice of a different one,
- or you can train a specialized reranker yourself, tailored to the problem.
Both approaches have advantages and disadvantages. The first one is faster, but (a) there is no guarantee that there is a model that we need, (b) if we agree on a model, we accept its accuracy in our problem. The approach involving training or retraining our own model will likely be much more costly due to the time needed to develop it. However, there is a good chance that such a model will be much more accurate than the available ones, which will improve the quality of the final RAG system. So what should we choose? It depends on the situation… 😉
Of course, in the reranking process, we are not limited to operating only on cross-encoder models. At this stage, we get potential fragments that contain the answer, so only our imagination limits us here in terms of what can be done… Is it worth using specialized models here? Absolutely.
(…) Matching the relevance of the chunk to the given question is a very important step. An inappropriate change in the ranking order of documents may result in texts containing important information being rejected just before they are submitted to GenAI, which can significantly spoil the final result.
Generating responses
And finally, we are here, at the stage that makes the biggest impression on the end user. It is only at this stage that GenAI comes into play—as an element that constructs the response, which is presented as an answer to the RAG system user.
All of the steps mentioned above constitute a stream of data preprocessing, searching, selection, and determining the relevance of partial results to the user’s query. It is these steps that largely determine whether the final answer will be relevant or not. Incorrectly selected data at this stage will cause the GenAI model to hallucinate. It is also important that the GenAI model we use to generate responses is also properly trained in the task of answering questions. When we talk about GenAI, we tend to think of instruction models. It is therefore important that such a GenAI not only understands the language and is able to respond in that language, but also responds appropriately to instructions. Its task will be to summarize all the fragments/chunks returned from the previous steps. So it is important that such a model is primarily able to respond to instructions for answering questions based on the context provided in the form of chunks.
Instruction models are usually very large models, starting with the smaller 8B (billions), through 70B, 405B, and more parameters. This brings us to another question — should we use an on-premises model or a cloud model? Of course, it all depends on the purpose of the system and the ability to transfer data via the internet to external services such as ChatGPT. If you choose a locally queried generative model, the question remains, as in all previous steps… the right model for the problem at hand 🙂 And what model? That’s a separate story.
(…) The previous steps are important, but equally important is the right choice of GenAI, which will generate the final response. It can ruin the whole impression.
Conclusion
Let’s put it all together 😉
It is safe to say that the quality of responses from such a system is strongly determined by the quality of the data used by the system. It is also important to identify good and bad quality data and standardize it for further processing. It is also important to select or train a specialized embedder and ensure proper indexing in databases. Additional meta-information about chunks can be very helpful during searches, e.g., limiting results to documents from a specific category. Matching the relevance of a chunk to a given question is a very important step. Inappropriate changes to the ranking of documents may result in texts with important information being rejected just before they are submitted to GenAI, which can significantly spoil the final result. The previous steps are important, but equally important is the appropriate selection of GenAI, which will generate the final answer. It is GenAI that can spoil the whole impression.
PPS.
And soon we will publish our GenAI model — pLLama, an LLama model trained in Polish 😉
Pingback: pLlama3 (8B + 70B) – GenAI dla polskiego – RadLab