
pLLama – generated using AI
Intro
In the last post, we mentioned the GenaAI model… Yes! Today we want to introduce you to our new model, or rather a family of models further trained on the Polish language: pLLama3-8B-chat, pLLama3-8B-creator, and pLLama3-70B. This time, we decided to further train models from the giants to make them handle language Polish.
First up were Llama-3-8B-Instruct and Llama-3-70B-Instruct from Meta.ai. This is an instruction model that can carry out commands given in the model’s prompt. The original model does not handle Polish very well. Sometimes it can write something in Polish, but it is difficult to force it to communicate fluently in language Polish. Interestingly, it can surprisingly well understand Polish commands, but it cannot construct a correct response.
We are making the 8B architecture models available in two configurations:
- radlab/pLLama3-8B-creator, a model that gives fairly short, specific answers to user queries;
- radlab/pLLama3-8B-chat – a model that is a talkative version, reflecting the behavior of the original meta-llama/Meta-Llama-3-8B-Instruct model..
Dataset
The fact that the original model could understand Polish commands was the spark that ignited our work on the model. We hypothesized that it would suffice to appropriately fine-tune the language layer while interfering as little as possible with the instruction layer.
However, as is often the case with large language models, the first problem arose: where to obtain data (especially available as instruction/chat conversation sets!) that would be sufficiently abundant and of the highest possible quality? For the Polish language, there is actually only one publicly available dataset for training an instruction model: alpaca-dolly-chrisociepa-instruction-only-polish. However, the size of this dataset did not allow for sufficient fine-tuning of the model.
Therefore, we developed a method to create a dataset structured as instructions, using other datasets available online. We prepared a set of approximately 650k Polish instructions that we fed to the model during training.
Additionally, we developed a training set for the DPO process, which contained 100k examples where we taught the model to select correctly written versions of texts over those containing language errors. The DPO training examples included a correctly written linguistic form (chosen) and an incorrectly written form (rejected) of the same text. It is worth noting that the DPO data was built in reverse – namely, for very high-quality texts (chosen), we prepared their corrupted counterpart (rejected).
Training Process
The training process was divided into two stages:
- Fine-tuning (FT) on a set of 650k Polish-language instructions, with the fine-tuning duration set to 5 epochs.
- After the FT stage, we further trained the model using DPO on 100k instructions for correct Polish writing; in this case, we set the training duration to 15k steps.
Fine-tuning the model on 650k was aimed at shifting the language layer of the fine-tuned model toward the Polish language. Unfortunately, due to the imperfect instruction set
Fun fact: the instruction set was generated ~95% automatically — using an early version of the trained model (in the 70B architecture) iteratively to assist in creating the set that we used to train this target model…
the model started actually speaking Polish and responding to instructions, but it sometimes made quite a lot of typos. That’s why we decided to further train the model with DPO. In DPO, we primarily wanted to achieve an improvement in the model’s language layer compared to the FT model. The optimization involved teaching the model to select the correct linguistic form and reject the incorrect one.
The graph below shows the loss function during the entire training process (8B model). The sudden drop in value at the beginning of the function may indicate a fairly quick adaptation of the model to the Polish language. And the entire, long-lasting training process is, de facto, refining the already existing linguistic details.
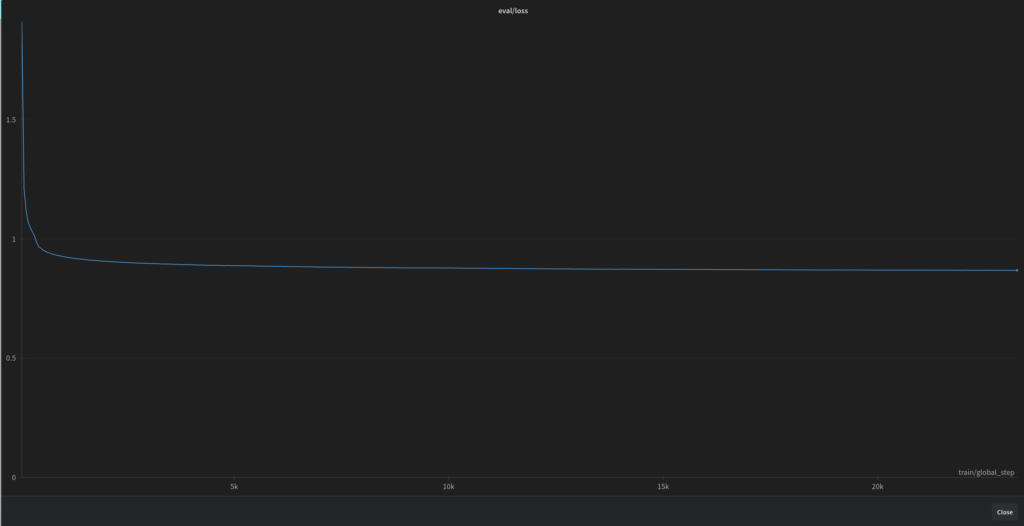
We trained the 8B models for 5 epochs, and the entire training process lasted over 19 days and 14 hours on a single RTX 4090 card.
Detailed metrics after completed fine-tuning (8B model):
| Metric | Value |
| eval/loss | 0.8690009713172913 |
| eval/runtime | 464.5158 |
| eval/samples_per_second | 8.611 |
| total_flos | 46121863674517000000 |
| train_loss | 0.8724352801788304 |
| train_runtime | 1695168.0431 |
| train_samples_per_second | 1.758 |
| train/epoch | 5 |
| train/grad_norm | 0.17023593187332153 |
| train/learning_rate | 6.584723441615452e-8 |
| train/loss | 0.8293 |
And the DPO metrics are as follows:
- eval/logits/chosen: 0.1370937079191208
- eval/logits/rejected: 0.07430506497621536
- eval/logps/chosen: -454.11962890625
- eval/logps/rejected :-764.1261596679688
- eval/loss: 0.05717926099896431
- eval/rewards/accuracies: 0.9372459053993224
- eval/rewards/chosen: -26.75682830810547
- eval/rewards/margins: 32.37759780883789
- eval/rewards/rejected: -59.134429931640625
- eval/runtime: 1,386.3177
- eval/samples_per_second: 2.838
- eval/steps_per_second: 1.42
The graph below shows the loss function during the entire training process of the model in the 70B architecture.
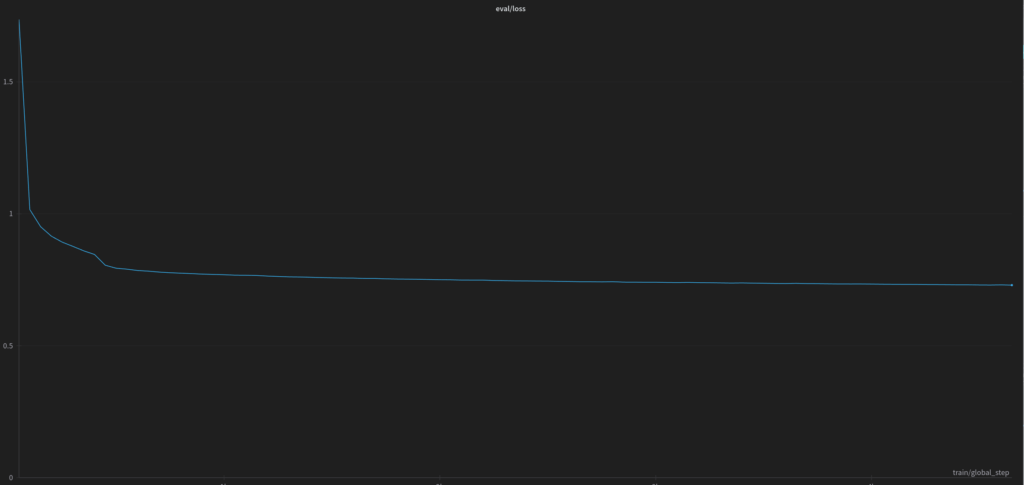
We also trained the 70B model for 5 epochs, and the entire training process lasted over 1 month and 5 days on a single RTX A6000 ADA 48GB card, while the metrics after completed fine-tuning:
- eval/loss:0.7297297716140747
- eval/runtime:6,364.4589
- eval/samples_per_second:0.628
- eval/steps_per_second:0.628
What after training?
Our models have one very interesting feature. At the moment, they can read text in any language and respond in Polish. That’s why one of them, which we named pLLama3-8B-creator , we employed to write articles for a certain project, which we’ll tell you about soon. Another one, pLLama3-8B-chat, also has its part in it 🙂 Enjoy!
Huggingface
Of course! We make the model available for free on our Hugging Face. The individual models:
radlab/pLLama3-8B-chatat: https://huggingface.co/radlab/pLLama3-8B-chatradlab/pLLama3-8B-creatoravailable: https://huggingface.co/radlab/pLLama3-8B-creatorradlab/pLLama3-70Bavailable: https://huggingface.co/radlab/pLLama3-70B
Bon appetit and welcome! 🙂
Pingback: pLlama3.2 (1B + 3B) – małe GenAI dla polskiego – RadLab
Pingback: pLLama3.1 8B — czyli średnio-duże a nawet małe GenAI dla Polskiego – RadLab
Pingback: Etyka i bezpieczeństwo w GenAI – RadLab